
Listcrawler. This powerful tool allows for the automated extraction of data from various online sources. Imagine effortlessly collecting product details from e-commerce sites, building comprehensive blog archives, or creating detailed website navigation maps – all without manual intervention. Listcrawlers offer a significant advantage in streamlining data acquisition, providing a wealth of information for analysis, research, and various other applications.
This exploration delves into the functionality, technical aspects, ethical considerations, and optimization strategies associated with listcrawlers, equipping you with a comprehensive understanding of this valuable tool.
From understanding the core functionalities and different target list types to navigating the technical intricacies of development, we will cover essential aspects, including the use of programming languages, libraries, and efficient data handling techniques. We will also address the crucial ethical and legal implications of web scraping, emphasizing responsible data acquisition and adherence to best practices. Finally, we will examine ways to optimize performance and illustrate the practical applications and output of a listcrawler through illustrative examples and visualizations.
Definition and Functionality of Listcrawler
A listcrawler is a type of web scraping tool designed to extract lists of data from websites. It systematically navigates a website, identifying and extracting structured data presented in list formats. This allows for the efficient collection of information that would otherwise require significant manual effort. Listcrawlers are particularly useful when dealing with large volumes of data presented in a consistent, list-like structure.Listcrawlers function by analyzing the website’s HTML source code to identify elements that represent lists.
This typically involves using techniques like CSS selectors or XPath expressions to target specific HTML tags (such as `
- `, `
- Website Navigation Menus: Extracting links from main navigation bars to understand website structure and content organization.
- Product Catalogs: Gathering product information such as names, descriptions, prices, and images from e-commerce sites.
- Blog Post Archives: Collecting titles, dates, and URLs of blog posts to analyze content trends or build a database of articles.
- Search Result Pages: Extracting URLs and titles from search engine results pages (SERPs) to analyze search rankings or build a link database.
- Directory Listings: Collecting business information (name, address, phone number) from online business directories.
- Respect robots.txt: The robots.txt file specifies which parts of a website should not be accessed by web crawlers. Always check and respect this file before initiating any scraping activity. Ignoring it is a clear indication of disregarding the website owner’s wishes and could lead to legal action.
- Adhere to website terms of service: Carefully review a website’s terms of service before scraping. Many explicitly prohibit automated data extraction. Violating these terms can lead to legal repercussions.
- Obtain explicit consent: Whenever possible, obtain explicit consent from individuals before collecting their personal data. This demonstrates respect for their privacy rights and helps avoid legal problems.
- Limit data collection: Only collect the data that is absolutely necessary for your project. Avoid collecting unnecessary personal information to minimize privacy risks.
- Use ethical scraping techniques: Avoid overloading a website’s servers with requests. Implement delays and rate limiting to prevent disruption. This shows respect for the website owner’s resources.
- Be transparent about data usage: Clearly state how you intend to use the collected data. This builds trust with both website owners and individuals whose data is being collected.
- Provide a mechanism for data removal: Allow individuals to request the removal of their data from your database if they wish.
- `, or even table rows) that contain the desired data. Once identified, the crawler extracts the text content within these list elements, often cleaning and formatting the data for easier use in downstream applications. The extracted data can then be stored in various formats, such as CSV, JSON, or a database.
Types of Lists Targeted by Listcrawlers
Listcrawlers are versatile and can target a wide range of list types found on websites. The specific target depends on the goals of the scraping operation.
Common targets include:
Real-World Applications of Listcrawlers
Listcrawlers find practical applications across various domains. The following table illustrates some examples, highlighting their benefits and potential drawbacks.
| Application | Target List Type | Benefits | Potential Drawbacks |
|---|---|---|---|
| Price Comparison Website | Product Catalogs (multiple e-commerce sites) | Automated price aggregation, competitive analysis, improved user experience | Website structure changes, rate limits, legal restrictions (terms of service) |
| Analysis Tool | Search Result Pages, Backlink Lists | ranking tracking, competitor analysis, backlink profile monitoring | API limitations, changes in search engine algorithms, potential for IP blocking |
| Market Research Firm | Product Reviews, Social Media Posts | Sentiment analysis, consumer opinion gathering, product development insights | Data bias, ethical considerations (user privacy), difficulty in verifying data accuracy |
| Academic Research | Scientific Publications, Citation Lists | Literature review, citation analysis, identifying research trends | Data inconsistencies, access restrictions (paywalls), potential for bias in data selection |
Technical Aspects of Listcrawler Development
Developing a robust and efficient listcrawler requires careful consideration of various technical aspects, from choosing the right programming languages and libraries to implementing effective data extraction techniques. The selection of tools directly impacts the crawler’s performance, maintainability, and scalability.Programming languages like Python and JavaScript are commonly employed due to their extensive libraries for web scraping and data manipulation. Python, in particular, offers powerful libraries such as Beautiful Soup and Scrapy, which simplify the process of navigating HTML structures and extracting relevant data.
JavaScript, often used in conjunction with browser automation tools like Puppeteer or Selenium, enables the interaction with dynamic websites that rely heavily on JavaScript for content rendering.
Programming Languages and Libraries
Python’s popularity in web scraping stems from its readability and the availability of specialized libraries. Beautiful Soup excels at parsing HTML and XML, providing an intuitive interface for navigating the document tree. Scrapy, a more comprehensive framework, offers features for managing requests, handling responses, and storing extracted data efficiently. It also incorporates mechanisms for handling errors and managing the crawling process.
JavaScript, coupled with browser automation tools, allows for handling dynamic content loaded via AJAX requests or JavaScript-based rendering, which often poses challenges for simpler scraping methods. Libraries like Cheerio, a fast and flexible HTML parser for Node.js, mirror the functionality of jQuery, making it a familiar choice for developers experienced with front-end web development.
Data Extraction Techniques, Listcrawler.
Extracting list items requires careful consideration of the website’s structure. Regular expressions, while powerful, can be brittle and require a deep understanding of the target website’s HTML. HTML parsing libraries, on the other hand, offer a more robust and maintainable approach.
Regular Expressions (Regex): Regular expressions can be used to extract list items when the list’s structure is relatively simple and consistent. However, they are less flexible and more prone to errors when dealing with variations in HTML structure.
import re
html = """
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
"""
items = re.findall(r"<li>(.*?)</li>", html)
print(items) # Output: ['Item 1', 'Item 2', 'Item 3']
HTML Parsing Libraries (Beautiful Soup): Beautiful Soup provides a more robust and flexible way to extract list items, handling variations in HTML structure more gracefully.
from bs4 import BeautifulSoup
html = """
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
"""
soup = BeautifulSoup(html, 'html.parser')
items = [li.text.strip() for li in soup.find_all('li')]
print(items) # Output: ['Item 1', 'Item 2', 'Item 3']
Listcrawler Development Flowchart
The flowchart below depicts the typical steps involved in building a listcrawler. Each step is crucial for creating a functional and efficient crawler.
The flowchart would visually represent the following steps:
1. Define Target Website and List Structure: Identify the website and the specific HTML elements containing the desired list items.
2. Develop Request Handling: Implement methods to fetch web pages, respecting robots.txt and implementing delays to avoid overloading the server.
3.
Do not overlook explore the latest data about kemeno party.
HTML Parsing: Utilize a suitable library (e.g., Beautiful Soup) to parse the HTML content and extract relevant data.
4. Data Extraction: Employ techniques like CSS selectors or XPath to target the list items precisely.
5. Data Cleaning and Transformation: Process the extracted data to remove irrelevant information, standardize formats, and ensure data quality.
6. Data Storage: Choose a suitable method to store the extracted data (e.g., database, CSV file).
7. Error Handling and Logging: Implement mechanisms to handle errors gracefully and log events for debugging and monitoring.
8.
Testing and Refinement: Thoroughly test the crawler on various scenarios and refine its logic as needed.
Ethical and Legal Considerations of Listcrawling: Listcrawler.

Listcrawling, while a powerful tool for data acquisition, raises significant ethical and legal concerns. The indiscriminate scraping of data can infringe on privacy rights, violate terms of service, and potentially lead to legal repercussions. Understanding these considerations is crucial for responsible and legal data collection.
Data Privacy and Permission
Respecting data privacy is paramount. Listcrawling often involves collecting personal information, such as email addresses, names, and locations. Scraping this data without explicit consent is a serious breach of privacy and can have severe consequences. Individuals have a right to control how their personal information is used, and failing to obtain their consent can lead to legal action under data protection laws like GDPR (General Data Protection Regulation) in Europe and CCPA (California Consumer Privacy Act) in California.
Companies can also face significant fines for violating these regulations. Ethical listcrawling necessitates prioritizing user privacy and obtaining explicit consent whenever possible, for example through opt-in forms or clearly stated data collection policies.
Legal Ramifications of Unauthorized Scraping
Scraping data from websites without explicit permission can lead to legal issues. Websites often have terms of service that explicitly prohibit scraping or automated data extraction. Violating these terms can result in legal action, including cease and desist letters, lawsuits, and even criminal charges in certain circumstances. Furthermore, copyright laws may protect the data itself, particularly if it’s presented in a structured format or involves creative content.
The legal landscape is complex and varies by jurisdiction, making it essential to consult legal counsel before engaging in large-scale listcrawling projects. Companies should be aware that the burden of proof for complying with legal regulations often rests with them.
Best Practices for Responsible Listcrawling
Responsible listcrawling involves adhering to ethical guidelines and legal requirements. This ensures the process respects both website owners and the individuals whose data is being collected.
Performance and Optimization of Listcrawlers
Listcrawlers, while powerful tools for data acquisition, can be significantly impacted by performance bottlenecks. Optimizing these tools is crucial for efficient data extraction, especially when dealing with large-scale web scraping projects. This section will explore common performance issues and strategies for improving the speed and efficiency of listcrawlers.
Common Performance Bottlenecks and Optimization Strategies
Several factors can hinder the performance of a listcrawler. Network latency, inefficient data processing, and poorly designed crawling strategies are common culprits. Addressing these issues requires a multi-pronged approach involving both code optimization and strategic design choices. For instance, network requests often dominate the execution time. Minimizing the number of requests, using efficient libraries for HTTP requests (like `requests` in Python), and implementing connection pooling can drastically reduce this overhead.
Furthermore, optimizing data parsing techniques is critical. Employing fast parsers like `Beautiful Soup` or `lxml` (for XML and HTML parsing) significantly improves processing speed compared to regular expressions for complex data structures. Finally, strategic crawling, such as prioritizing important pages and avoiding unnecessary requests, improves efficiency. Employing techniques like breadth-first search or depth-first search based on the specific needs of the project further enhances performance.
Consider using asynchronous programming or multi-threading to handle multiple requests concurrently, but be mindful of the target website’s robots.txt file and terms of service to avoid overloading the server.
Handling Large Datasets
Extracted data from listcrawlers can quickly grow to massive sizes. Efficiently handling these large datasets requires careful planning and the use of appropriate technologies. One approach is to process data incrementally, storing it in a database or a distributed file system instead of loading the entire dataset into memory at once. This approach, combined with techniques like data chunking and streaming, allows for processing of terabyte-sized datasets without memory exhaustion.
Databases such as PostgreSQL or MongoDB offer excellent scalability and performance for storing and querying large amounts of structured and unstructured data. Alternatively, cloud-based solutions like Amazon S3 or Google Cloud Storage provide scalable and cost-effective storage for massive datasets. The choice depends on factors like data structure, query requirements, and budget constraints. For example, if the data is highly structured and requires complex queries, a relational database like PostgreSQL might be preferred.
If the data is less structured and requires fast insertion and retrieval, a NoSQL database like MongoDB might be more suitable.
Error Handling and Retry Mechanisms
Robustness is paramount in listcrawlers. Network interruptions, server errors, and changes in website structure are inevitable. Implementing effective error handling and retry mechanisms is essential for ensuring the crawler’s reliability. A robust listcrawler should gracefully handle various exceptions, such as connection errors, HTTP errors (404, 500), and parsing errors. A simple retry mechanism involves attempting the failed request after a short delay.
Exponential backoff strategies, where the delay increases exponentially with each retry attempt, can help avoid overwhelming the server during temporary outages. Furthermore, implementing mechanisms to detect and handle changes in website structure, such as using flexible parsing techniques and regularly updating the crawler’s logic, enhances the long-term reliability of the system. Consider using logging to track errors and successes, facilitating debugging and monitoring the crawler’s performance.
A well-designed logging system can help identify recurring errors and pinpoint areas for improvement. For instance, if a particular website consistently returns a 403 error (forbidden), the crawler might need to adjust its user-agent or implement a more sophisticated authentication mechanism.
Illustrative Examples of Listcrawler Output
This section provides concrete examples of the data a listcrawler can extract and how that data can be presented. We will focus on a hypothetical e-commerce website selling electronics, demonstrating the output, visualization, and user interface design possibilities.
Listcrawlers are powerful tools for extracting structured data from websites. The output depends heavily on the target website’s structure and the listcrawler’s design, but generally involves a structured dataset representing the extracted information.
E-commerce Product Catalog Extraction
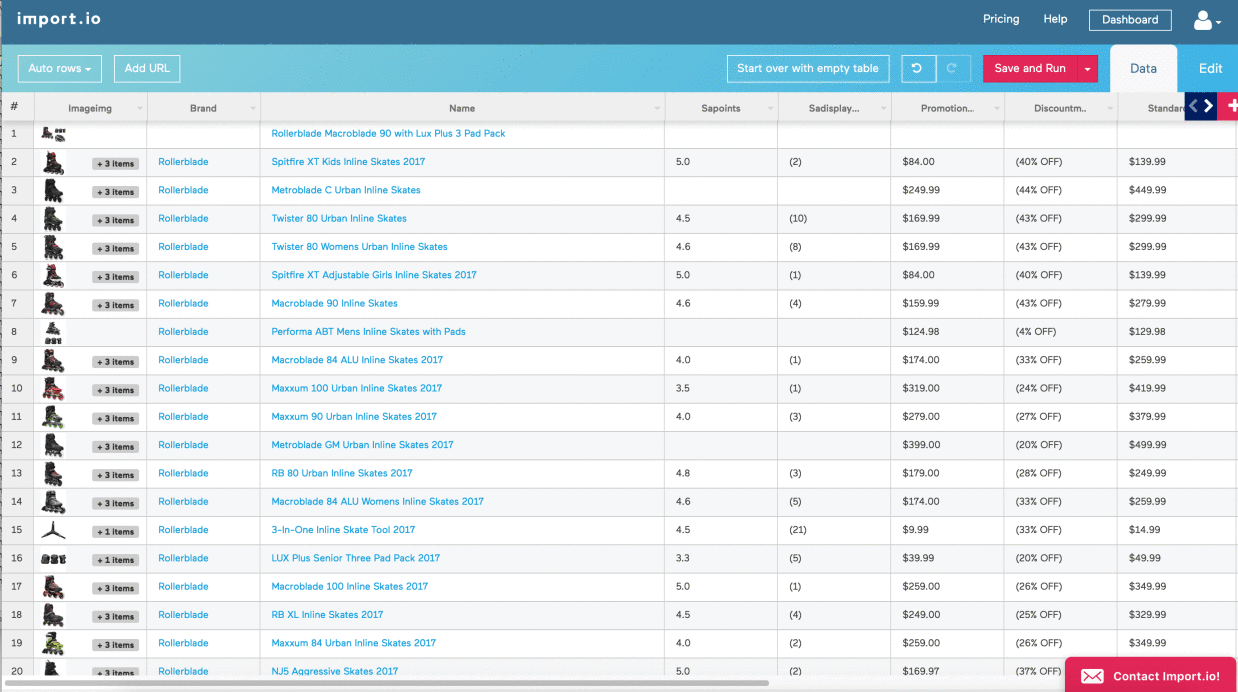
A listcrawler targeting an electronics e-commerce site’s product catalog might extract data such as product name, price, description, manufacturer, and image URLs. The following table shows a sample of the extracted data:
| Product Name | Price | Description | Manufacturer | Image URL |
|---|---|---|---|---|
| High-Definition 4K TV | $999.99 | 65-inch LED Smart TV with HDR support. | TechGiant | https://example.com/images/tv1.jpg |
| Wireless Noise-Cancelling Headphones | $249.99 | Comfortable and immersive listening experience. | AudioPro | https://example.com/images/headphones1.jpg |
| Gaming Laptop | $1499.99 | Powerful laptop for gaming and professional use. | PowerPC | https://example.com/images/laptop1.jpg |
Data Visualization: Price Distribution Chart
A bar chart could effectively visualize the price distribution of the extracted products. The x-axis would represent price ranges (e.g., $0-$250, $251-$500, $501-$1000, etc.), and the y-axis would represent the number of products within each price range. This chart would provide a clear overview of the price range of products offered by the e-commerce site. This allows for quick identification of price concentration and potential market trends.
Sample User Interface Design
The user interface could present the extracted data in a tabular format, similar to the table above, allowing users to filter and sort the data by different criteria (e.g., price, manufacturer, product name). A search bar would enable quick searching of specific products. Advanced features could include data export options (CSV, Excel) and charting capabilities, allowing users to generate charts and graphs directly from the extracted data.
The UI would utilize a clean and intuitive design, with clear labels and easily accessible functionalities. Navigation elements would allow users to browse through pages of results if the dataset is extensive.
In conclusion, listcrawlers represent a powerful tool for efficiently gathering data from the web. Understanding their functionality, technical implementation, ethical considerations, and optimization techniques is crucial for effective and responsible usage. By adhering to best practices and respecting website terms of service, we can leverage the capabilities of listcrawlers to streamline data collection processes and gain valuable insights from online resources.
This comprehensive overview aims to equip you with the knowledge and understanding necessary to effectively and responsibly utilize this powerful technology.


